ダン・アリエリーの論文の一つに再現性が無い。
調査の結果、データが全部捏造されたものだという。
どうしてこうなった。
ダン・アリエリーへの疑い
ベストセラーとなった行動経済学の本に『予想どおりに不合理』がある。このブログでも何度かお勧めしている本で、読んだ人も多いだろう。

本書の著者、ダン・アリエリーが共著者である論文について、データ捏造の疑いがかけられ話題となっている。
実験の主導者であるアリエリーは、「データが捏造されていること」については同意しているが、問題のデータは研究パートナーの「保険会社からもらったもの」であり、自分および共同執筆者たちはプライバシーの観点からデータ収集・データ入力・データのマージには関与していないと言っている*1。
本件はデータの不正を暴く過程が面白いのだが、研究の題材が面白さに輪をかける。この研究のテーマは「不正を減らす方法」である。アリエリーは予想以上に不合理な行動をとってしまったのか、それともただの被害者なのか。続報が気になってしかたない。
不正を減らす研究の不正
今回のデータ捏造の指摘は、匿名研究者たちによるものである。分析に使われたデータも公開されているので、興味がある人は自分で確認するといいだろう。
問題の論文は、「署名の位置」によって不正の割合が変わるというものだ。人は質問に答えるとき、回答は正しいものであると宣誓に署名してから回答するほうが、回答してから署名するよりも正直に回答する。そうアリエリーらは考え、検証を行った。

先に学内での署名効果を検証したアリエリーたちは*2*3、より実社会で試そうと考え、大手損害保険会社に話をもちかけた。署名効果を活用すれば、保険の不正請求を減らすことができるかもしれない。そして保険会社から、自動車保険の記入用紙で実験させてもらうことになったのである。
この用紙は、顧客が現在の走行距離を申告するための用紙である。保険会社はこれをもとに顧客の過去1年間の走行距離を計算する*4。年間の走行距離が短いほど保険料は安くなるため、顧客には実際より短い走行距離を記入する不正を行うインセンティブがある。

アリエリーたちは、手に入れた2万枚の用紙を2つに分け、署名欄を異なる配置にした。半分には「ここに記入した内容が真実であることを約束します」という文言と署名欄を用紙の下部に配置し、もう半分は文言と署名欄を上部に配置した。それ以外は全く同じである。
2種類の用紙は2万人の顧客にランダムに配布され、しばらくしたら返送されてきた。これでデータが手に入り*5、分析が始められる。

ではこのデータにどのような問題があり、なぜ捏造があったと言われたのか。データの異常を端的にまとめると以下の通りだ。
- 年間走行距離の分布が0から50,000マイルまでの一様分布
- 普通は正規分布になる
- 去年 (Baseline) の累計走行距離は四捨五入されているのに、今年 (Update) の累計走行距離は四捨五入されていない
- 走行距離の申告は手書きであるため、多くの人が四捨五入して下2,3桁を0にするのが一般的
- データの半分はフォントがCalibriで、もう半分はCambriaになっている
- CalibriのデータとCambriaのデータはペアになっており、ペアの差は1,000マイル以内
- Cambriaのデータは去年の累計走行距離でも四捨五入されていない
つまり以下のようにデータが捏造されたと、例の記事は結論づけている。
- 去年のCalibriデータに0~1,000の乱数を加え、去年のCambriaデータを生成する
- 倍にした去年のデータに0~50,000の乱数を加え、今年の全データを生成する
従って去年のデータの半分が捏造で、今年のデータは全部捏造というわけだ。

もう一点付け加えるなら、年間走行距離がアリエリーらの仮説に合うよう、さらに手を加えられていると考えられる。というのも、年間走行距離が0~50,000の一様分布であるならば、署名位置が下だろうと上だろうと平均は同じになるはずだからだ。
元データが配布されているので、試しに1台目の年間走行距離の分布について、署名が下と上で色分けしたものを作ってみた。
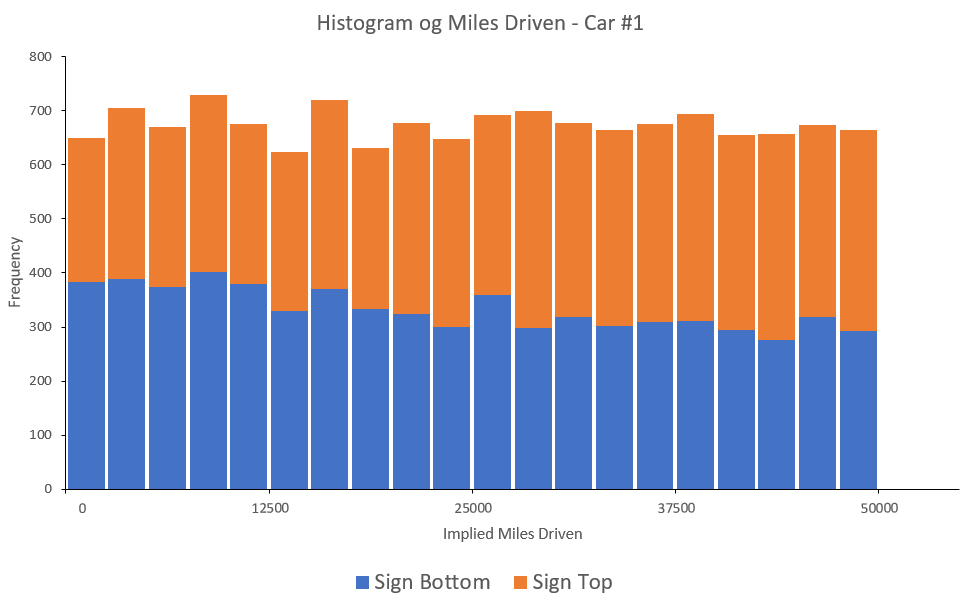
用紙の上に署名させた方が、仮説通り正直に (長く) 走行距離を回答する形になっている。極端に偏りがあるのではなく、比率がジワジワと入れ替わるような形になっているのが面白い。割とデータの扱いが雑であることを考えると、乱数を生成した後でいい感じの比率になるようにラベリングしたのではないかと思う。
ともあれ、本件はかなり悪質な捏造と言えるだろう。データの解釈をちょっといじったとか、都合の悪いデータを無視したとか、そんなかわいいものではない。全てが乱数なのだから。
一体どうしたらこんな不正ができるのだろうか。そこでダン・アリエリーの著書を手にとってみた。
嘘とごまかしの行動経済学
ダン・アリエリーは本件にぴったりな本を出している。その名も『ずる 嘘とごまかしの行動経済学』である。人がどのように不正を行うのか、行動経済学の観点から解説した本だ。

合理的経済学においては、人は費用便益分析をもとに不正を行うか判断するとしている。これはノーベル賞受賞者の経済学者ゲーリー・ベッカーが提唱した概念で、不正を行うことによる費用 (不正が発覚する確率 × 発覚した時の罰) と便益を比較し、得だと判断したら不正を働く、というものだ。ここに善悪の入る隙間はない。

しかし、アリエリーはこのモデルに異をとなえる。多くの人は「ちょっとした不正」をする一方で、バレない自信があっても大胆な悪事を働くことはめったに無い。合理的犯罪モデルでは費用が同じなら得られる金額が大きいほど不正をすることになるが、実際は違うのだ。
合理的犯罪モデルでは説明できないことを、アリエリーらは様々な実験で示している。問題を解かせて、正答数に応じて報酬を出す実験では、正答数をごまかすことができる場合でも、被験者たちは全問正解とはせず、実力よりちょっと高い点数を申告した。目が不自由な人に市場で買い物をしてもらう実験では、顧客の目が見えないことが分かっていても、店員たちは質の良い野菜をわざわざ選んで渡していた。まったくもって非合理的である。
そこでアリエリーは、人の行動は2つの相反する動機づけによって駆動しているのではないか、と述べている。
- 自分のことを立派な人物だと思いたい (自我動機)
- 不正をすることで利益を得たい (金銭的動機)

ここでポイントとなるのは、名誉と利益のどちらか片方を選ぶのではなく、うまく両立させるように人は認知的柔軟性を発揮させるということだ。ようするに不正を行う場合でも、何らかの理由をつけて正当化するのである。そうすれば名誉を守りつつ利益を得ることができる。

アリエリーは認知的柔軟性によって研究データをいじった自らの事例を紹介している。
それは意思決定に関する実験だった。ある条件の成績水準が、別の条件の成績よりずっと高くなると予想していた。実験はほとんど予想通りの結果となったが、成績が高くなるはずの条件で1人だけ成績は並外れて悪かった。データを確認したことろ、実験に酔っ払って参加した男のデータだと分かった。彼の意思決定能力が低いのは、実験の条件ではなく酩酊のせいである。男のデータを除外してみると結果の見栄えは良くなった。めでたしめでたし。
しかし数日後、アリエリーはこの判断は誤りだったのではないかと思うようになる。結果を見てからルールを追加してデータを除外するのは正しい行為と言えるのか、と。結局アリエリーは実験をやり直した。除外のルールを設けるのは、実験を行う前にやるべきである。

アリエリーは酔っ払いのデータを除外するとき、認知的柔軟性によって自分の行為を正当化していたと述べている。科学の発展のため、真実を明るみに出すために、問題のあるデータを除外するのだ、と。だがその背後には、予想どおりの結果が欲しいという、利己的な動機があったとも。
このように人が不正を働くときは、正当化を行っている。したがって正当化しやすいと不正を行いやすいし、その逆もしかりである。よってアリエリーは、間接的であるほど自分を欺いて正当化しやすく、不正を行いやすいと述べている。酔っ払いの件はデータを偽造するのではなく、異常値を除去するだけ。しかも除去の有無に関わらず、全体的な結果は変わらない。やってしまっても不思議ではない。
では今回のデータ捏造は? スライムのような認知的柔軟性と圧倒的な創造性を持ってしても正当化するのは難しそうだ。どうしてこうなった。
サイコパスか被害者か
データを捏造したのはいったい誰なのか。俺の知る限り、現時点では不明である。ただ客観的に最も怪しいのはダン・アリエリーその人だ。
当たり前のことであるが、アリエリーには自説を補強する結果がほしいというインセンティブがある。保険会社とデータとやり取りしたのは本人も言っている通り、アリエリーただ一人だ。そしてアリエリーが研究チームにデータを共有した時点で、今回の捏造は行わている。
しかし、だ。もしアリエリーが犯人だとしたら、そんな100%真っ黒なデータの研究をなぜ著書で紹介したのかと言いたくなる。しかも『ずる 嘘とごまかしの行動経済学』なんてタイトルの本で。本の内容を全否定するような所業を、どんな顔で書いたというのか。

加えて今回のデータ捏造が発覚した経緯も考慮すると、より謎が深まる。研究データが公開されたのは、2020年に「2012年の自動車保険の実験は再現ができなかった」という論文*6が発表された時である。その2020年の論文の著者には、ダン・アリエリーも含まれている。もしアリエリーがデータを捏造したのなら、なぜ自ら再現実験をしたのか。そして捏造したデータを公開したのか。自爆行為であるとしか思えない。
そうすると、アリエリーの言い分通り、保険会社がデータを捏造したと考えるほうが、行動経済学的には納得がいく。考えられる理由は面倒だからだ。今回の走行距離の調査は「用紙への記入」である。つまり誰かが用紙からExcelにデータを入力する必要がある。用紙は全部で2万枚*7。けっこう大変だ。そしてアリエリーのやりたいことは、保険会社も知っていた*8。
「おい、お前これを全部Excelに入力しておけよ」
マジかよ、全部で何枚あるんだよこれ
こんなのいつまで経っても終わるわけないじゃん
しかも通常の業務じゃなくてどっかの学者の実験だろ
他に優先すべき仕事もあるのに、なんで俺がやらないといけないんだよ……
……これどれも似たような数値だな、走行距離だし当然か
もしかして乱数でもバレないんじゃね
早く仕事が終わったほうが上司も喜ぶし、もう乱数でいいだろ
えーっと、Excel 乱数 っと (ッターン!)
なんか容易に想像がつく。
しかしアリエリーも守秘義務を理由に提携した保険会社の名前も明かさないし、保険会社の担当者は全員退職しているとか言っているので*9、やっぱり怪しい。結局のところ、続報待ちとしか言えない。
終わりに
2ヶ月ほど前の記事で、ダン・アリエリーの『予想どおりに不合理』を紹介し、こう書いていた。
行動経済学と言えば、有名な『ファスト&スロー』もセール対象なのだが、書かれている内容の多くに再現性が疑われている*10ことを知ってしまったので勧めにくい。幸い、「なぜ休みを延期することはこれ程までに辛いのか」で紹介したプロスペクト理論は大多数の実験で再現されている*11のが救いか。
では『予想どおりに不合理』はどうなのかというと、英語版Wikipediaと「予想どおりに不合理 再現性」で検索した感じでは特に問題視されていない。しかし調べ方が足りない可能性は十分にある。仮に再現性が無かったからといって健康や財産を失うわけではないのだから過度に恐れる必要は無いが*12、盲信するのは止めた方がいいだろう。
プライムデーのKindle本から使い勝手の良い6冊 - 本しゃぶり
再現性がないことは予想どおりだったが、まさか完全にデータが捏造されたパターンが出てくるとは予想以上だった。行動経済学の全てが信用ならないとは言わないが、やはり話半分に聞いておいたほうが良いように思える。ドヤ顔で紹介するのは慎んでおこう。
しかしこうなるとTwitterでも言われていたのだけど、やはり早川書房に『Science Fictions: Exposing Fraud, Bias, Negligence and Hype in Science』の邦訳を出してほしくなる。早川書房はダン・アリエリー著作を始め、行動経済学関係の本をいろいろ出しているので。まあ、どこの出版社からだろうと、出たら読むのは間違いない。
")
{kind=link}
{kind=link}
参考書籍
上でも貼ったが、問題の研究が紹介されているダン・アリエリーの著作。ある意味で今読むのが一番面白い。
再現性の危機の記事
*2:The Dishonesty of Honest People: A Theory of Self-Concept Maintenance - Nina Mazar, On Amir, Dan Ariely, 2008
*3:なおこれは後の追試で再現性がないことが示されている。Registered Replication Report on Mazar, Amir, and Ariely (2008), 2018
*4:Data Coladaの記事では、基準となるタイミング (Baseline) と実験後のタイミング (Update) の間にどれくらい時間が経過しているかは不明であり、顧客によって異なると書いてある。一方でこの実験を紹介しているアリエリーの著書では、はっきりと「過去一年間の走行距離」と書かれている。本記事では分かりやすさを優先して本の表記を採用し、「去年」「今年」という書き方をした。
*5:手に入ったデータ数はN = 13,488。
*6:Signing at the beginning versus at the end does not decrease dishonesty | PNAS
*7:研究に使われたデータは13,488枚分だが。
*8:アリエリーは保険会社の本部へ出向き、重役たちと保険の不正請求を減らす方法を出し合ったと言っている。
*9:Dan Ariely Retracts Honesty Study Based On Fake Data
*10:Thinking Fast and Slow | Replicability-Index
*11:Massive cross-national replication of Kahneman and Tversky's prospect theory https://t.co/vWgce4tvNa "With over 4,000 participants from 19 countries, we find that Kahneman and Tversky's 1979 findings replicate in the vast majority of analyses." Image: https://t.co/pSAE1QUJfE https://t.co/4sMl7D5IzH / Twitter https://mobile.twitter.com/SteveStuWill/status/1262542765440643072
*12:本書の内容を元に何かをするならその限りではないが。例えば政策に反映させるとか。